7 并发编程 并发编程的目的:提高程序处理任务,处理请求的速度/能力。
并发编程的方式:
7-1 开启多进程的两种方式
方式1:Process
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import timefrom multiprocessing import Processdef func (name ):print (f'{name} is start' )1 )print (f'{name} is done' )if __name__ == '__main__' :'jack' ,))print ('主进程结束' )
方式2:继承Process, 重写方法run
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import timefrom multiprocessing import Processdef func (name ):print (f'{name} is start' )2 )print (f'{name} is done' )class MyProcess (Process ):def __init__ (self, name ):super ().__init__()def run (self ): if __name__ == '__main__' :"jack" )print ('主进程结束' )
7-2 主进程等待子进程结束 示例1:使用join()优雅的等待子进程结束,不要使用time.sleep
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timefrom multiprocessing import Processdef func (name ):print (f'{name} is start' )1 )print (f'{name} is done' )if __name__ == '__main__' :'jack' ])1 ) print ('主进程结束' )
示例2:等待多个子进程,使用不当造成串行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import timefrom multiprocessing import Processdef func (name ):print (f'{name} is start' )1 )print (f'{name} is done' )if __name__ == '__main__' :for i in range (5 ):str (i)])print ('主进程结束' )
示例3:示例2优化版
1 2 3 4 5 6 7 8 9 10 if __name__ == '__main__' :for i in range (5 ):str (i)])for p in ps:print ('主进程结束' )
示例4:等待总耗时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import timefrom multiprocessing import Processdef func (i ):print (f'{i} is start' )print (f'{i} is done' )if __name__ == '__main__' :for i in range (1 , 4 ):for p in ps:print ('主进程结束' )print (time.time() - start)
7-3 守护进程 主进程将一个子进程设置为守护进程,守护进程就会在主进程结束时随之结束不再运行 。
守护进程内无法再开启子进程 ,否则抛出异常:AssertionError: daemonic processes are not allowed to have children在开启子进程之前将其设置为守护进程 主进程代码运行结束,守护进程随即终止 ,不受别的子进程的影响。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from multiprocessing import Processimport timedef task ():print ('i am coming' )2 )print ('i am backing' )if __name__ == '__main__' :True 0.1 )print ('i am master' )
示例2:各子进程相互独立,不会因为一个子进程设置为守护进程而影响另一个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from multiprocessing import Processimport timedef task (i ):print (f'{i} am coming' )print (f'{i} am backing' )if __name__ == '__main__' :for i in range (1 , 4 ):if i == 3 : True 2 )print ('master' )
7-4 进程隔离内存空间 进程之间内存空间是隔离的,即进程j间数据是隔离的,互不影响 。
因为这是两个独立的名称空间。子进程有其自己的名称空间,只是修改其名称空间内全局变量的值,而不影响父进程自己名称空间全局变量的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from multiprocessing import Process100 def task ():global money666 print ('子' , money)if __name__ == '__main__' :print ('主' , money)
7-5 互斥锁 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是有问题的。
示例1:进程不共享数据导致的数据混乱问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from multiprocessing import Process, Lockimport json, time, randomdef search (i ):with open ('data' , 'r' , encoding='utf8' ) as f:print ('用户%s查询余票:%s' % (i, dic.get('ticket_num' )))return dicdef buy (i ):1 , 3 )) if dic.get('ticket_num' ) > 0 :'ticket_num' ] -= 1 with open ('data' , 'w' , encoding='utf8' ) as f:print ('用户%s买票成功' % i)else :print ('用户%s买票失败' % i)if __name__ == '__main__' :for i in range (1 , 11 ):
共享带来的是竞争,竞争带来的结果就是错乱。控制的方式就是加锁处理,即每个进程依次使用资源。
示例2:互斥锁,保证数据安全
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from multiprocessing import Process, Lockimport json, time, randomdef search (i ):with open ('data' , 'r' , encoding='utf8' ) as f:print ('用户%s查询余票:%s' % (i, dic.get('ticket_num' )))def buy (i, mutex ):1 , 3 ))with open ('data' , 'r' , encoding='utf8' ) as f:"ticket_num" ]if ticket_num > 0 :'ticket_num' ] -= 1 with open ('data' , 'w' , encoding='utf8' ) as f:print ('用户%s买票成功' % i)else :print ('用户%s买票失败' % i)if __name__ == '__main__' :for i in range (1 , 11 ):
加锁处理的结果就是:将并发变成串行,牺牲效率,保证数据的安全
7-6 多线程 基础知识:
一个程序的运行过程是一个进程,每个进程自带一个控制线程 。
进程是一个资源单位,线程是具体的执行单位 。进程相当于一个车间,线程相当于车间内的流水线,车间内可以有多条流水线,即一个进程内可以有多个线程。
多线程之间共享数据资源,相当于一个车间内有多条流水线,都共用一个车间的资源。
1 2 3 4 5 6 进程: 资源单位(起一个进程是在内存空间中开辟一块独立的空间)
为什么使用多线程:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。
示例:开线程的两种方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from threading import Threaddef task ():print ('我是子线程' )if __name__ == '__main__' :print ('我是主线程' )class MyThread (Thread ):def run (self ):if __name__ == '__main__' :print ('我是主线程' )
7-7 线程共享内存空间
补充:线程的知识点和进程的知识点类似,可以举一反三的学习。
同一个进程下的多个线程是共享当前进程下的数据资源的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from threading import Thread100 def func ():global n200 print ('子线程:' , n) if __name__ == '__main__' :print ('主线程:' , n)
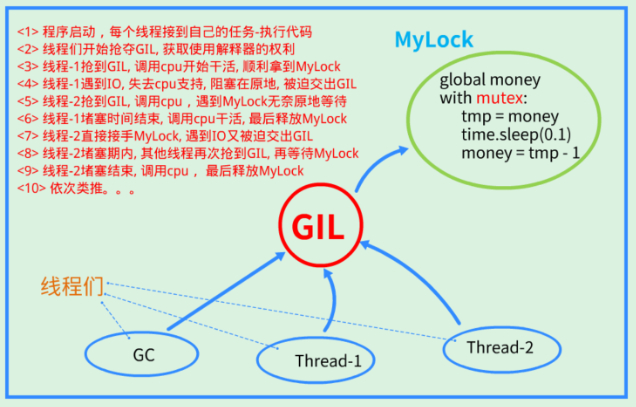
7-8 GIL 全局解释器锁(GIL, Global Interpreter Lock)。
结论:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
总结:
GIL不是python语言的特性,它是Cpython解释器引用的一个概念。 GIL本质是一把互斥锁,是将线程从并发变为串行,牺牲效率保证数据安全。 保护不同的数据要加不同的互斥锁,GIL保护的是解释器级别的数据安全。
首先明确:python多线程无法利用计算机的多核优势 。
但是python多线程可以实现并发的,且不是所有的场合都要使用多核的。
场合:
对于计算密集型,多进程优于多线程 (多进程的并行计算优势突出了)对于IO密集型,多线程优于多进程 (开进程的开销大缺陷放大了)
结论:python多线程无法使用多核优势,不等于多线程一无是处 。
7-9 进程池和线程池 基础知识:
无论是开进程还是开线程,都需要消耗资源,只不过开线程的比开进程的消耗更少。
不可能无限制的开进程或线程,因为计算机硬件的资源是有限的。
为了保证服务器一定的处理能力,只能采取池的概念。
池:就是限制开进程或开线程的数量,比如开多线程,限制最多开10个线程,那这个线程池的大小就是10,也就是说最多只有10个线程在干活。
示例1:线程池和进程池的基本使用(都是使用concurrent.futures模块)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from concurrent.futures import ThreadPoolExecutorimport timeimport randomdef task (n ): 1 , 5 ))print (n ** 2 )if __name__ == '__main__' :5 ) for i in range (1 , 10 ):
示例2:增加回调函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from concurrent.futures import ThreadPoolExecutorimport timeimport randomdef task (n ): 1 , 5 ))return n ** 2 def call_back (future ): print ('call_back>>>:' , future.result())if __name__ == '__main__' :5 )for i in range (1 , 10 ):
示例3:map函数快速获取结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from concurrent.futures import ThreadPoolExecutorimport timeimport randomdef task (n ): 1 , 5 ))return n ** 2 if __name__ == '__main__' :5 )map (task, range (1 , 10 )) for r in rets:print (r)
总结 :
池子一旦造出来后,固定了线程或进程 ,不会再变更,所有的任务都是这些进程或线程处理。
这些进程或线程不会再出现重复创建和销毁的过程。 任务的提交是异步的,异步提交任务的返回结果 应该通过回调机制来获取。 回调机制就相当于,把任务交给一个员工完成,它完成后主动找你汇报完成结果。
7-10 协程【伪】 协程是单线程下的并发,协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级;单线程内就可以实现并发的效果,最大限度地利用cpu
示例1:基于yield实现代码块切换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def f1 ():yield 1 yield from f2()yield 2 def f2 ():yield 3 yield 4 for i in generator:print (i)
示例2:使用asyncio实现协程【官方推荐】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import asyncioasync def f1 ():print (1 )await asyncio.sleep(2 ) print (2 )async def f2 ():print (3 )await asyncio.sleep(2 )print (4 )
严格来说,其实Python并没有协程,是一种伪协程,因为python的协程只是一种异步编码思想,而没有一个完整生命周期