4 面相对象【重中之中】
面向对象不是什么语法关键字,也不是什么函数方法,
而是一种思想,具备这种思想,才能写Python,
换言之:
如果不具备这种思想,就写不好Python !!!
如果不具备这种思想,就写不好Python !!!
如果不具备这种思想,就写不好Python !!!
通过本文可以对Python 面向对象有写启蒙,但是具体要根据项目实际场景应用才能深刻体会。
4.1 一切皆对象【重点】
- Python是一门
面向对象语言
- Python中一切皆对象
- 无法深刻理解
面向对象就无法用好Python
- 自定义的类实例化对象,其实像基本数据类型(int\string\list\dict等)、函数、类都是对象,都可以按照对象的方式来操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hello(self):
print(f"My name is {self.name}")
jack = Student("jack", 18)
print(type(jack))
jack.say_hello()
print(jack.age)
ll = []
ll.append(123)
def foo():
pass
print(type(foo))
|
type查看对象类型- 通过dir函数查看对象下面有哪些属性和方法
- 通过id()查看变量的内存地址
1
2
3
4
5
6
7
8
9
10
11
| num1 = 400
num2 = 500
print(num1 is num2)
n1 = 100
n2 = 100
print(n1 is n2)
stu1 = Student("jack", 18)
stu2 = Student("jack", 18)
print(stu1 is stu2)
|
4.2 面向对象的封装思想【重点】
- 基本数据类型int/str/bool的功能单一,于是有了容器型数据类型list/tuple/dict/set等
- 独立的代码块使用起来冗余,于是又了函数,便于特定功能代码块的组织管理、重复使用
- 面向对象:将程序进一步整合,对象封装了数据属性和方法属性(数据和功能)即对象也是“容器”
- 进一步,许多同类型的对象,是不是也被
抽象成了类,所以类也是“容器”,封装了同类型对象共有的数据和功能,可以重复使用
4.3 绑定方法和非绑定方法【有用】
- python中,类内部定义的函数分为两大类:绑定方法和非绑定方法
- 绑定方法有两个:绑定给对象的方法,绑定给类的方法;绑定给谁的方法,谁在调用的时候就不用传第一个参数,比如说self就是绑定给对象的方法,实例化对象调用的时候就不用传第一个参,cls就是绑定给类的方法,类使用的时候就不需要传第一个参
- 非绑定方法:类型普通函数,谁都可以使用,遵循普通函数的传参,目的只是为了封装在一起,如:静态方法。就是谁都可以调用且调用的时候不需要传第一个参
1
2
3
4
5
6
7
8
9
10
11
12
| class Student():
def __init__(self,name,age):
self.name=name
self.age=age
def edit_name(self,new_name):
self.name = new_name
@classmethod
def get_student(cls,name,age):
return cls(name,age)
@staticmethod
def add(a,b):
return a+b
|
4.4 类装饰器property【了解】
python中的property就是一个类装饰器,有两个用途:
- 用途一:将函数属性伪装成数据属性
- 用途二:统一数据属性的查、改、删除操作【把数据转成对象去操作】
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class People():
def __init__(self,name,w,h):
self.__name=name
self.w=w
self.h=h
@property
def bmi(self):
return self.w / (self.h**2)
obj1 = People('jack',66,1.75)
print(obj1.bmi)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
class Poeple:
def __init__(self, name, w, h):
self.__name = name
self.w = w
self.h = h
@property
def name(self):
return self.__name
@name.setter
def name(self, value):
if type(value) is not str:
print('必须传入str类型')
return
self.__name = value
@name.deleter
def name(self):
print('不能删')
obj1 = Poeple('jack', 66, 1.75)
print(obj1.name)
obj1.name = 'aaa'
del obj1.name
|
4.5 cached_property【了解】
- 将一个类方法转换为特征属性,一次性计算该特征属性的值,然后将其缓存为实例生命周期内的普通属性。
- 类似于对
property 但增加了缓存功能。对于不可变的高计算资源消耗的实例特征属性来说该函数非常有用
- 内置包functools下面的类装饰器cached_property
cached_property 是一个 Python 装饰器,它可以用于定义一个缓存的属性,这意味着属性的值在第一次访问后会被计算,并将结果缓存起来,后续的访问会直接返回缓存的值,从而避免重复计算。
cached_property 装饰器可以在需要计算代价较高的属性时使用,以提高性能和效率。
在使用 cached_property 装饰器之前,你需要先安装一个名为 cached-property 的第三方库,它提供了这个装饰器的实现。
这个用的少
4.6 属性查找顺序【了解】
属性或者方法的查找顺序的原则
- 先从对象自身身上找,有则使用;没有的话,再从类上找,有则使用;类上也没有的话就报错则报错AttributeError
示例1:查看对象或类有哪些属性或方法可以使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| class Student:
school = 'PKU'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
self.course = None
def get_info(self):
print('学生信息:名字:%s 年龄:%s 性别:%s' % (
self.name,
self.age,
self.gender
))
def select_course(self, new_class):
print('正在选课')
self.course = new_class
print(Student.__dict__)
print(Student.school)
print(Student.get_info)
print(Student.__dict__["school"])
print(Student.__dict__["get_info"])
stu1 = Student("jack", 18, "男")
print(stu1.name)
print(stu1.get_info)
print(stu1.__dict__)
stu1.haha = "123"
stu1.add = lambda x: print(x)
|
4.7 隐藏属性【有用】
- 如果类的设计者不想某些属性被访问,就可以将该属性给隐藏起来。
- 隐藏属性可以隐藏类中的公有属性和对象的私有属性,对象访问会报错,
- 实现方法:使用双下划线开头命名的属性将会被隐藏
- 另:单下划线开头的属性和方法类似于保护属性,类内可以访问,类外也可以访问但不会提示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class MyClass:
def __init__(self):
self.public_attr = 42
self._protected_attr = 23
self.__private_attr = "secret"
obj = MyClass()
print(obj.public_attr)
print(obj._protected_attr)
print(obj._MyClass__private_attr)
|
示例2:在类外部无法直接访问双下滑线开头的属性,在类内部可以访问到
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class Foo:
...
def __f1(self):
print('from test')
def f2(self):
print(self.age)
print(self.__name)
self.__f1()
obj = Foo('jack', 18)
obj.f2()
|
示例3:在类定义阶段,双下划先开头的属性会发生变形
示例4:只在定义阶段发生形变
1
2
3
4
5
6
7
8
9
10
|
class Foo:
__x = 1
...
Foo.__y = 2
print(Foo.__y)
|
4.8 开发接口【了解】
- 定义属性的目的是为了被使用,所以隐藏属性的目的不是单纯的隐藏,隐藏式为了更好的使用。
- 想要这些属性被使用,那就必须提供一个对外的接口,(没有被隐藏的属性)
- 隐藏数据属性:将数据隐藏起来就限制了类外部对类内数据的直接操作,然后类内应该提供相应的接口(函数方法)来允许外部间接的操作数据,接口之上呢可以附加额外的逻辑来对数据的操作进行严格的判断,比如说加上各种 if 啊,如果不符合就raise抛出异常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class Student:
def __init__(self, name):
self.__name = name
def get_name(self):
print(self.__name)
@property
def name(self):
return self.__name
def set_name(self, new_name):
if type(new_name) is not str:
raise TypeError("名字必须是字符串类型")
self.__name = new_name
stu = Student("jack")
stu.set_name("111")
stu.get_name()
print(stu.name)
|
4.9 python多继承【概念】
- 继承是面向对象思想的另一个特性。它的存在是为了解决类与类之间代码重复的问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
class Student:
school = 'PKU'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
def select_course(self):
print(f'学生:{self.name}正在选课。。。')
class Teacher:
school = 'PKU'
def __init__(self, name, age, sex, level):
self.name = name
self.age = age
self.sex = sex
self.level = level
def score(self):
print(f'老师:{self.name}正在打分。。。')
class PkuPeople:
school = 'PKU'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class Student(PkuPeople):
def select_course(self):
print(f'学生:{self.name}正在选课。。。')
class Teacher(PkuPeople):
def __init__(self, name, age, sex, level):
super().__init__(name, age, sex)
self.level = level
def score(self):
print(f'老师:{self.name}正在打分。。。')
|
4.10 深度优先和广度优先【知道就行】
1
2
3
4
5
6
7
8
9
|
- 经典类:没有继承object类的子类,以及该子类的子类子子类。。。
- 新式类:继承了object类的子类,以及该子类的子类子子类。。。
- object类提供了一些常用内置方法的实现,如用来在打印对象时返回字符串的内置方法__str__
- 通过类的内置属性__bases__可以查看类继承的所有父类
|
继承的菱形结构
概念一:经典类和新式类
概念二:深度优先和广度优先
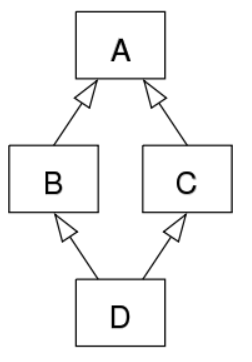
如上图,继承关系成菱形
4.11 Mixin混合机制【有点用】
- 允许将某个单一功能封装在独立的类中,然后通过一个类多重继承这些功能类,混合在一起,实现代码的复用和模块化
- 单一职责,一个类只关注单一功能
- 多重组合,通过多继承将多类混合在一起
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class LoggingMixin:
def log(self, message):
print(f"Log: {message}")
class EmailMixin:
def send_email(self, subject, body):
print(f"Sending email to {self.email}: {subject}, {body}")
class User(LoggingMixin, EmailMixin):
def __init__(self, username, email):
self.username = username
self.email = email
user = User("alice", "alice@example.com")
user.log("User created")
user.send_email("Welcome", "Welcome to our website!")
|
- Mixin不是单一功能,只是一种编程思维,通常被定义为混合的类,类名在命名的时候都会在后面加一个Minxin来表示这个类是混合类
Minx使用规范
- 首先它必须表示某一种功能,而不是某个物品,python 对于mixin类的命名方式一般以 Mixin, able, ible 为后缀。
- 其次它必须责任单一,如果有多个功能,那就写多个Mixin类,一个类可以继承多个Mixin。
- 它不依赖于子类的实现;子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。
- 通常Mixin的类放在子类括号内的右边(表示非核心功能)
4.12 派生和组合
派生:在使用父类原有的方法的基础上,增加新的内容(用super( )方法重写父类方法)
子类可以原封不动的使用父类的属性/方法,也可以重写父类的属性/方法,还可以在使用父类的属性/方法的同时,添加新的内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class People:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def __init__(self, name, age, gender, code):
People.__init__(self, name, age, gender)
self.code = code
stu = Student("jack", 18, "男", 10111)
print(stu.__dict__)
class Student(People):
def __init__(self, name, age, gender, code):
super().__init__(name, age, gender)
self.code = code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class Student:
def __init__(name, age):
self.name = name
self.age = age
class Coursr:
pass
stu = Student('jack', 18)
course_obj = Course()
stu.course = course_obj
|
4.13 限制子类必须实现的方法【重点】【抽象概念】–设计模式的一种
在父类中定义的方法,需要子类必须实现,此时就有两种限制方法
方式1:使用模块abc,(即抽象类abstract class的缩写)
就是加ab的装饰器的方法,然后你在继承的时候,必须去定义这个方法,不然实例化的时候就会出错
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import abc
import abc
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod
def talk(self):
pass
class Cat(Animal):
def talk(self):
pass
cat=Cat()
|
方式2:使用 NotImplementedError
1
2
3
4
5
| class Animal:
def talk(self):
raise NotImplementedError("该方法必须被实现")
|
4.14 isinstance
当我们需要获取一个对象的类型是,可以使用`type()
当我们需要判断一个对象是否是指定类型时可以使用isinstance函数快速判断。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class People:
def __init__(self, name):
self.name = name
p = People("jack")
print(isinstance(p, People))
a = 10
print(isinstance(a, int))
print(isinstance(a, (str, int)))
除此之外,还有一个函数可以判断类与类之间的父子关系,`issubclass`
class Animal:
def __init__(self, name):
self.name = name
class People(Animal):
pass
print(issubclass(People, Animal))
print(issubclass(Animal, People))
print(issubclass(People, (list, Animal)))
print(issubclass(People, People))
|
4.15 反射机制【重点】
- 首先: 反射机制是什么?反射机制
首先,python是一门动态语言,python的反射机制就是指,可以在程序运行的时候获取程序的属性方法,而不需要在编码时明确知道这些对象、方法名、或属性名的具体信息,反射使得你可以在程序运行时动态地获取、操作和探索对象的属性和方法。python的反射机制核心4点:
1
2
3
4
5
6
| hasattr(object, "x")
getattr(object, name, default=None)
setattr(object, 'x属性名', 'y属性名')
delattr(object, 'y属性名')
|
- 1、getattr( object, name,default=None):
- 2、hasattr():
- 3、setattr():
- 4、delattr():
- 5、dir(): 这个常用,这个就时获取对象所有属性
- 6、exec():和eval():函数
python中使用反射非常方便,仅需要使用4个内置函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
class Ftp:
def get(self):
pass
def set(self):
pass
def delete(self):
pass
ftp = Ftp()
cmd = input('请输入指令:').strip()
if cmd == 'get':
ftp.get()
elif cmd == 'set':
ftp.set()
elif cmd == "delete":
ftp.delete()
else:
print('指令不存在')
hasattr(obj, 'x')
getattr(object, name, default=None)
setattr(x, 'y', 'v')
delattr(x, 'y')
class Ftp:
...
ftp = Ftp()
cmd = input('请输入指令:').strip()
if hasattr(ftp, cmd):
getattr(ftp, cmd)()
else:
print('指令不存在')
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class Foo(object):
staticField = "HAHA"
def __init__(self):
self.name = 'jack'
def func(self):
return 'func'
@staticmethod
def bar():
return 'bar'
print getattr(Foo, 'staticField')
print getattr(Foo, 'func')
print getattr(Foo, 'bar')
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import sys
def s1():
print('s1')
def s2():
print('s2')
this_module = sys.modules[__name__]
print(hasattr(this_module, 's1'))
getattr(this_module, 's2')
|
1
2
| print(dir(obj))
print(obj.__dict__[dir(obj)[index]])
|
作用呢?
动态调用和访问对象的属性,getattr() setattr() hasattr()这些都可以随时修改和获取对象的属性
动态获取token
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| class ApiClient:
def __init__(self):
self.token = None
def login(self, username, password):
response = self.send_request('/login', {'username': username, 'password': password})
self.token = response['token']
def send_request(self, endpoint, data):
pass
def request_with_token(self, endpoint, data=None):
if self.token:
headers = {'Authorization': f'Bearer {self.token}'}
else:
headers = None
return self.send_request(endpoint, data, headers)
def test_api():
client = ApiClient()
client.login('your_username', 'your_password')
token = getattr(client, 'token', None)
assert token is not None, "Token not obtained"
response = client.request_with_token('/some_endpoint', {'param': 'value'})
assert response['status'] == 'success', "Request failed"
|
4.16 单例模式【重点】–设计模式的一种
- 首先,单例模式是什么? 是软件的一种设计模式,
- 目的:无论调用多少次产生的实例对象,都是指向同一个内存地址,仅仅只有一个实力(一个对象)
- 方式: 首先实现单例模式的手段有很多终端鹅,但总的原则是什么,是包装你定义的一个类,只要实例化一个对象,下一次再实例化对象的时候,就直接返回你已经实例化过的这个对象,不再做实例化的操作,
所以这里关键的一点就是,你该如何去判断这个类是否已经实例化过一个对象
- 这里介绍两类方式:
- 一个是通过模块导入的方式;
- 二个事通过一个魔法方法去判断方式
- 应用的场景呢?什么时候用单例模式去创建一个类呢?
网站计数器,确保全局只有一个计数器实例化对象,用来记录网站的总访问次数。
**配置管理器:配置信息的管理,确保你整套代码中,只有一个配置管理器的实例,用于统一管理配置信息,比如说同意发送请求,所有的请求都是通过这个实例化对象去访问的,
**
日志记录器:全局代码运行的时候确保只有一个日志记录器的实例化对象,用来记录这套代码运行时的日志记录
数据库连接池:保证整套代码运行的过程中,只有一个数据库连接池的实例,方便管理对数据库的同意连接和同意关闭连接池
- 注意一下:单例模式虽然可以在很多特定场景下体统便利,但不可以过度依赖单例模式导致代码的可测试性和可维护性降低
通过模块导入的方式怎么实现:
1
2
3
4
5
6
7
8
9
|
class Singleton:
def __init__(self):
print("Singleton instance created")
singleton_instance = Singleton()
|
在另一个文件中导入这个模块
1
2
3
4
5
6
7
8
9
10
11
|
import singleton
instance1 = singleton.singleton_instance
instance2 = singleton.singleton_instance
print(instance1 is instance2)
|
通过类绑定方法的方式来实现单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
class Singleton:
_instance = None
def __init__(self):
if Singleton._instance is not None:
raise ValueError(
"Singleton instance already exists")
Singleton._instance = self
print("Singleton instance created")
@classmethod
def get_instance(cls):
if cls._instance is None:
cls._instance = cls()
return cls._instance
instance1 = Singleton.get_instance()
instance2 = Singleton.get_instance()
print(instance1 is instance2)
|
补充:这种方式实现的单例模式有一个明显的bug;bug的根源在于如果用户不通过绑定类的方法实例化对象,而是直接通过类名加括号实例化对象,那这样不再是单利模式了。