2 数据结构 2.1基本数据结构 可变:列表、字典、集合
不可变:数字、浮点、字符串、元组(需元组内无可变)
直接访问:数字
顺序访问(序列类型):字符串、列表、元组
Key值访问(映射关系):字典
2.2 深浅拷贝 【什么是拷贝】:原封不动地复制一份新的,在不同的内存地址上,修改旧的不会影响新的。
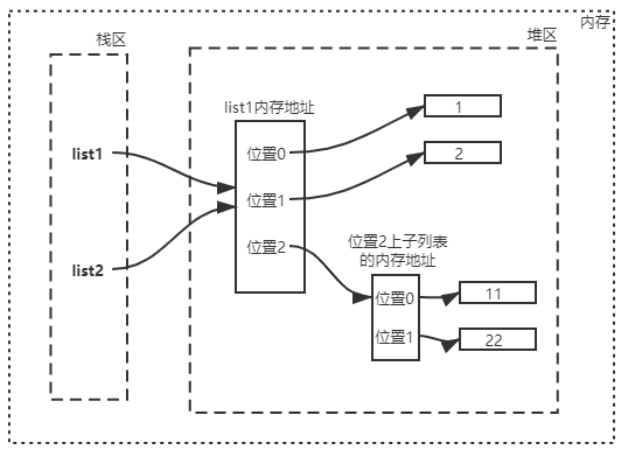
变量赋值不是拷贝
1 2 3 4 list1 = [1 , 2 , [11 , 22 ]]
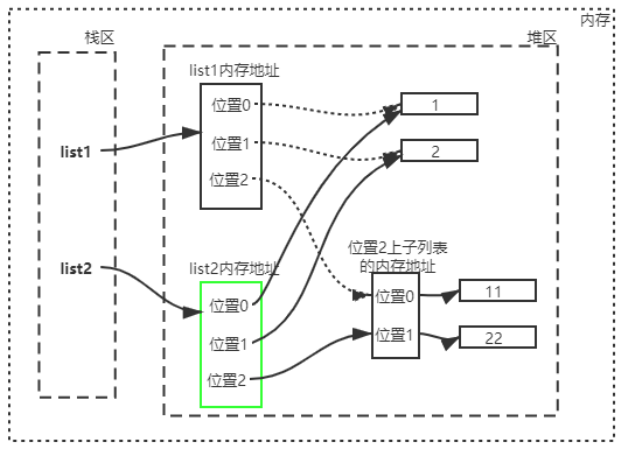
执行浅拷贝操作,将在开辟一块新的内存空间,然后将list2绑定到这块内存空间上。
新内存空间中有三个位置用来存放其三个元素的内存地址。
新拷贝的列表的三个位置分别绑定旧列表三个位置上的元素的内存地址。
所以修改旧列表的中的字列表时,会影响新列表中的值,因为它们还同步一部分内存空间。
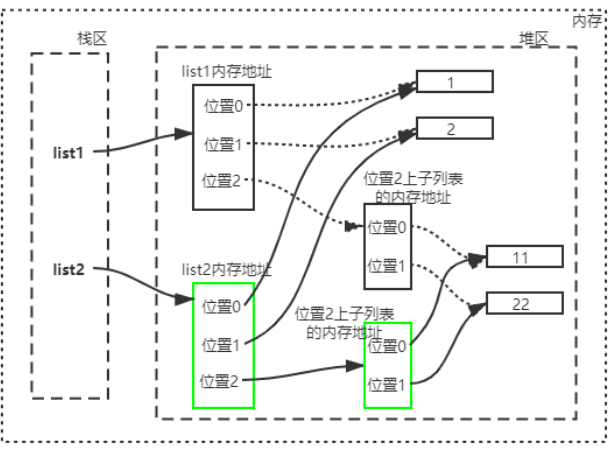
【深拷贝】:使用copy.deepcopy()
1 2 3 import copy 1 , 2 , [11 , 22 ]]
深拷贝时,当元素是可变数据类型时,会重新开辟一块内存空间,存放这个元素对象的内存地址,且该元素内部的可变数据类型也会再重新开辟内存空间,层层检测,层层拷贝。
此时,新旧列表的子元素都不会共享内存地址,所有不会相互影响。
深拷贝不会,互相独立的
【总结】
深浅拷贝讨论的拷贝对象是可变数据类型
深浅拷贝的区别在于:是否区分元素的可变还是不可变类型的判断;
列表的切片也是浅拷贝,copy模块的copy.copy()函数是浅拷贝操作,和列表的内置方法copy()功能相同。
容器型数据类型的拷贝都存在深浅拷贝问题。
深浅拷贝没有有优缺点。
2.3 推导式 【推导式】也成生成式(comprehensions)是 Python 独有的一种高级特性,它可以使用简单的一行代码实现列表、字典等数据类型的创建或数据类型的转换等任务。
1 2 3 4 5 6 7 for i in range (1 , 101 ):for i in range (1 , 101 )]
【列表推导式】
1 2 3 4 5 6 7 for i in range (10 ) if i % 2 == 0 ]"name" :"jack" , "age" : 18 }for key in a]
【字段推导式】
1 2 3 4 5 6 2 for i in range (5 )}1 ,2 ], (3 ,4 )]dict (x for x in li)
【集合推导式】
1 2 3 4 5 for i in range (1 ,5 )}set (i for i in range (1 ,5 ))
【元组推导式】
1 2 3 4 5 6 7 8 9 tuple (x for x in range (1 ,5 )) 3 ,4 ,5 ,6 ]tuple (x for x in nums)
list_a = [m for i in iterable for m in i ]
2.4.1 三元表达式 在Python中,三元表达式是一种简洁的条件表达式,用于根据条件选择不同的值。它的语法形式如下:
1 value_if_true if condition else value_if_false
其中,condition 是一个条件表达式,如果条件为真,则返回 value_if_true;否则返回 value_if_false。
1 2 3 4 5 x = 10 20 if x > y else yprint (max_value)
三元表达式通常用于简单的条件选择,可以在一行代码中快速进行条件判断和值的选择。它比使用完整的 if-else 语句更为简洁和紧凑。
2.4 namedtuple 有名元组【重点】 可以想象成一个元组但是他有名字,也叫具名元组
兼顾元组的特性,一旦定义不能被修改
可以通过对象点的方式访问,。
1 2 3 4 5 6 7 8 9 10 11 12 13 from collections import namedtuple"Point" , ["x" , "y" ]) 11 , y=22 ) print (p[0 ], p[1 ])print (p.x, p.y) print (p._asdict()) "x" : 11 , "y" : 22 }print (Point(**d)) 100 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from collections import namedtuple'Person' , ['name' , 'age' , 'city' ])'name' : 'Alice' ,'age' : 25 ,'city' : 'New York' print (person_tuple.name) print (person_tuple.age) print (person_tuple.city)
首先通过 namedtuple 函数定义了一个名为 Person 的有名元组类,它有三个字段:name、age 和 city。然后,定义了一个字典 person_dict,包含了相应的字段值。接下来,使用 ** 运算符将字典中的键值对作为参数传递给 Person 类的构造函数,创建了一个有名元组对象 person_tuple。
优点:通过访问有名元组对象的字段,可以获取字典中对应的值。
缺点:
1、不可变性(定义了就不能变)
2、额外的内存消耗:需要开辟额外的内存空间来存储字段名称和值,大规模数据时可能会影响性能
3、有限的功能:轻量级,缺乏灵活性,
4、不支持动态字段操作:不可以动态添加和删除
2.5 OrderedDict 顺序字典 python3.6之前的字典是不按插入先后顺序排序的,但是可以实现这种功能,就是OrderedDict类型字典
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class OrderedDict (dict ):'Dictionary that remembers insertion order' pass from collections import OrderedDict"jack" , age=18 )print (order_dict)for k, v in order_dict.items():print (k, v)for i in range (5 ): 10 for k, v in order_dict.items():print (k, v)def move_to_end (self, key, last=True ):""" Move an existing element to the end (or beginning if last is false). Raise KeyError if the element does not exist. """ "age" )print (order_dict.keys())
python3.6之后的字典默认按照插入的先后顺序展示
2.6 defaultdict 不会错误的字典 普通的字典访问不存在的键时会抛出keyError异常
defaultdict类型字典在访问不存在的key时不会异常,会返回default
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 示例1 :基本使用from collections import defaultdictint ) 1 ] = 100 print (d[1 ])print (d[2 ]) list ) print (d[2 ]) 2 :default_factory可以为可调用对象from collections import defaultdictdef default_value ():return 500 1 ]print (v1)
2.7 deque 双向队列 deque双向队列(double-end queue)类似于list的容器
deque 可以快速的在队列的头部和尾部添加、删除元素
list只能在尾部追加,不可以从头部加元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 dq = deque()100 )300 ) for i in dq:print (i)print (dq.pop())print (dq.popleft()) 2 ) from collections import deque1 , 2 , 3 , 4 , 5 ]print (dq.popleft())
2.8 二分查找
最简单的查找算法是遍历,但遍历的效率太低了。
二分查找(也叫折半查找)
二分查找的原理是,选择一个有序列表,确定最左边的值和最右边的值和最中间的位置值,比较待查元素和中间位置值,这样每次比较就可以排除一般的查找范围。
二分查找的前提是有序,特点是速度快,大数据查找的时候快一点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def query_target (list_test ,target ):0 len (list_test)-1 2 if list_test[mid]==target:return midelif list_test[mid]>target:1 else :1 return -1
优点:简单,高效快速
缺点:要求被查列表必须有序、递归占用空间、不适合动态数据
应用场景:有序列表、静态数据、快速查找
2.9 冒泡排序 实现的逻辑:从第一个元素开始,逐个比对每一个元素,如果自己比对比的元素大,那么自己的索引就前进一个
1 2 3 4 5 6 7 8 9 10 a = [1 , 56 , 65 , 23 , 12 , 23 , 5 , 7 , 3 , 9 ]print (a)len (a) for i in range (0 ,l): for j in range (0 ,l-i-1 ): if a[j]>a[j+1 ]: 1 ]=a[j+1 ],a[j]print (a)
优点:简单易懂,稳定,原地排序,不会生成新的列表 ,不改变相等值的位置
缺点:性能差,不适合大规模数据排序
应用场景:小规模排序,
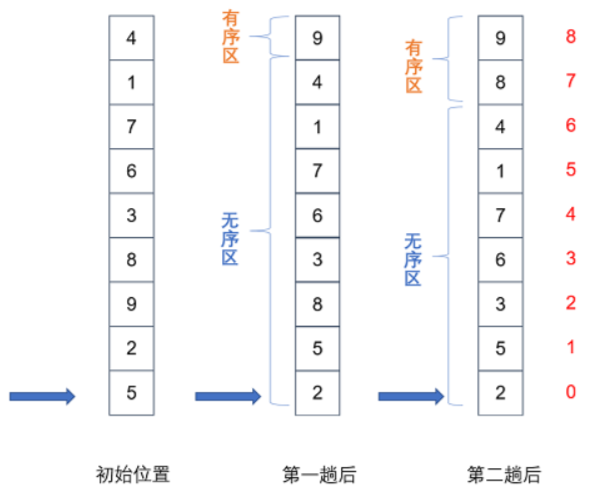
2.10 选择排序 实现逻辑:
1、找到数据中最小的元素,将这个元素与第一个元素交换位置
2、在剩下元素中找最小的元素,将这个元素与剩余元素中的第一个元素交换位置
3、循环
1 2 3 4 5 6 7 8 def selection_sort (list1 ):len (list1)for i in range (n-1 ):for j in range (i+1 ,n):if list [j]<list1[min_index]:
【代码实现v2】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def select_sort (li ):for i in range (len (li) - 1 ): for j in range (i+1 , len (li)): if li[j] < li[min_index]:
2.11 python内置排序算法 sort() 原地排序,不会生成新的数据,只对列表用
sorted() ,生成一份新数据,对所有可迭代对象都用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 5 , 2 , 8 , 1 , 4 , 5 ]6 , 1 , 7 , 3 , 9 , 2 ]True ) sorted (l2)def my_sort (x ):return x["id" ]"id" : 5 }, {"id" : 1 }, {"id" : 3 }]lambda x: x["id" ])is set (add! tooverride)3 : 1 , 5 : 2 , 1 : 3 }lambda x: weights[x["id" ]])