【Golang】go语言之并发编程基础(goroutine、channel、SELECT)
并发编程
go中的串行和并行还有并发的概念
- 串行(Sequential):
- 串行是一种执行方式,串联行走,按照顺序逐一的执行任务或者操作,
- 在串行执行中,每个任务必须等待前一个任务执行完了之后才能开始执行
- 场景:串行执行通常用于单核或者单线程环境,其中一次只能执行一个任务,意味着任务要找现行顺序执行,一个接一个,直到所有的任务都完成
- 串行执行通常具有可预测行,因为任务的执行顺序是确定的,
- 缺点就是在多核系统中,无法充分的利用硬件资源
- 并行(Parallel):
- 并行也是一种执行方式 ,
- 多个任务或者操作可以同时的执行,不必等待前一个任务完成,
- 充分利用多核处理器或者多线程环境的优势
- 并发(Concurrency):
- 并发是一个更广泛的概念,在同一时间段内处理多个任务,但不一定要求同时执行。在并发中,任务可以交替执行,每个任务都有自己的执行周期,并发通常涉及的是多个独立的执行线程、进程或者协程。
- 并发不一定需要多核处理器,它可以在单核处理器上模拟通过快速切换执行线程来实现。
- 并发通常用于提高系统的吞吐量、资源利用率和响应性,特别是IO密集型应用中。
- 并发任务之间可能需要协调、同步和共享数据,因此需要小心处理并发问题,如竞争条件和死锁等
- 总结:
- 串行是指按顺序执行任务的方法,不涉及多个任务之间的交替执行
- 并行是多个任务同时执行的方式,通常需要多核处理器或多线程环境
- 并发是多个任务在同一时间段内处理的方式,可以是交替执行,通常涉及多线程或协程、并需要处理并发相关问题。
【拓展】并发模型
- 主流并发模型无外乎三种
- 1、多线程:每个线程一次处理一个请求,线程越多可并发处理的请求数就越多,
- 但是在高并发下,多线程的开销会比较大
- 2、协程:无需抢占式的调度,开销小,可以有效的提高线程的并发性,从而避免了线程的缺点那部分
- 3、基于异步回调的IO模型:异步编程,当遇到密集IO的时候,等待,让其他程序继续跑
- 1、多线程:每个线程一次处理一个请求,线程越多可并发处理的请求数就越多,
goroutine的基本概念
- 概念:是一种轻量级的线程,用于执行程序并发任务,与传统线程相比,goroutines更加轻量且消耗更少,
routine:常规;例行程序;日常工作
与创建线程相比,创建成本和开销都很小,每个goroutine的堆栈只有几kb,并且堆栈可根据程序的需要增长和缩小(线程的堆栈是需要指明和固定的),所以go语言从语言层面就支持高并发。
- 并发执行:多个goroutines可以同时运行,且不需要显式的线程管理,有助于充分利用多核处理器,提高程序的性能
- 轻量级:goroutines比传统线程更轻量。这个轻量可以通俗理解为创建和销毁他们的成本很低,通常数百上千的goroutines可以在同一个程序中运行而不会引发性能问题
- 并发通信:goruntines之间的可以通过通道(channel)进行安全的并发通信,通道是goroutines之间交换数据的一种机制,避免了竞争条件和协调任务
- 并发模型:Go 语言的并发模型是基于 CSP(Communicating Sequential Processes)的,它强调通过通信来共享数据,而不是共享数据来通信。这种模型使并发编程更加安全和可维护。
- 如何启动 goroutine:要启动一个goroutine,只需要在函数或方法调用前加上关键字’go’ 即可创建一个新的goroutine来执行该函数,程序继续执行后续任务,而不会等待goroutine完成
1 | |
- 程序执行的背后:当程序启动的时候,只有一个goroutine来调用main函数,可以理解为主goroutine,新的goroutine通过go语句进行创建
1 | |
- tips:DelayPrint里面的sleep ,会导致第二个goroutine阻塞或者等待吗?
- 答案肯定是不会
- 当程序执行go func()的时候,只是简单的调用然后就立即返回了,并不关心函数内部发生的事情,所以不同的goroutine直接不影响,main会继续按顺序执行语句,所以两个go rountine同时在跑,但是肯定是第一个gorounine先执行
1 | |
- 这里从输出内容看得出来,当程序碰到go func()的时候,并不管go func()的内容,直接就去执行后面的代码了
通道(channel)
概念:
- 通道是什么:是一种数据结构,所以通道可以用var 来声明数据的类型的
- 干什么?:通道是一种在goroutines之间传递的数据结构,它类似于一个队列,同于在通道与通道之间发送和接收数据的
- 通道的类型:道中传递的数据必须与通道的类型匹配。通道类型使用
chan关键字,如chan int表示一个整数类型的通道。 - 发送和接收:通道的基本操作有发送(
send)和接收(receive)。通过通道发送数据时,数据会被发送到通道,然后可以在另一个 Goroutine 中接收。 - 阻塞:当发送或接收操作发生时,它们可能会阻塞当前 Goroutine,直到有另一个 Goroutine 准备好接收或发送数据。这有助于同步不同 Goroutines 之间的操作。
- 从channel中读取数据,如果channel之前没有写入数据,也会导致阻塞,直到channel中被写入数据为止
强调一下:
- 通道是在传递数据,而不是在赋值数据,当通道A 体内的数据,传给了B的时候,A就没有数据了,就空了,B就接收到了B就有了
接收操作(<-channel)、发送操作(channel <- data)或关闭操作(close(channel))。
声明:
1 | |
类型:通道理论上来说可以分2种
无缓冲通道和缓冲通道
无缓冲通道:无缓冲通道上的发送操作将会被阻塞,直到另一个goroutine在对应的通道上执行接收操作,此时值才传送完成,两个Goroutine都继续执行(发送时阻塞,直到接收才会畅通继续)
- 定义的时候,不给大小就是一个无缓冲通道了,ch:=make(chan int) int后面不设容量
1 | |
- 通道可以用来连接goroutine,这样一个的输出是另一个输入。这就叫做管道。
1 | |
- 单向通道:
- 单向就是指限制一头通信,比如限制仅接收,或者限制仅发送数据
- 双向通道可以修改为单向通道,反之不行
- 当程序则够复杂的时候,为了代码可读性更高,拆分成一个一个的小函数是需要的。
goroutine的通道默认是阻塞的,那么有什么办法可以去缓解阻塞呢:?
答案:加一个缓冲区
- 缓冲通道: 一个有容量的通道,可以定义他的容积大小。
1 | |
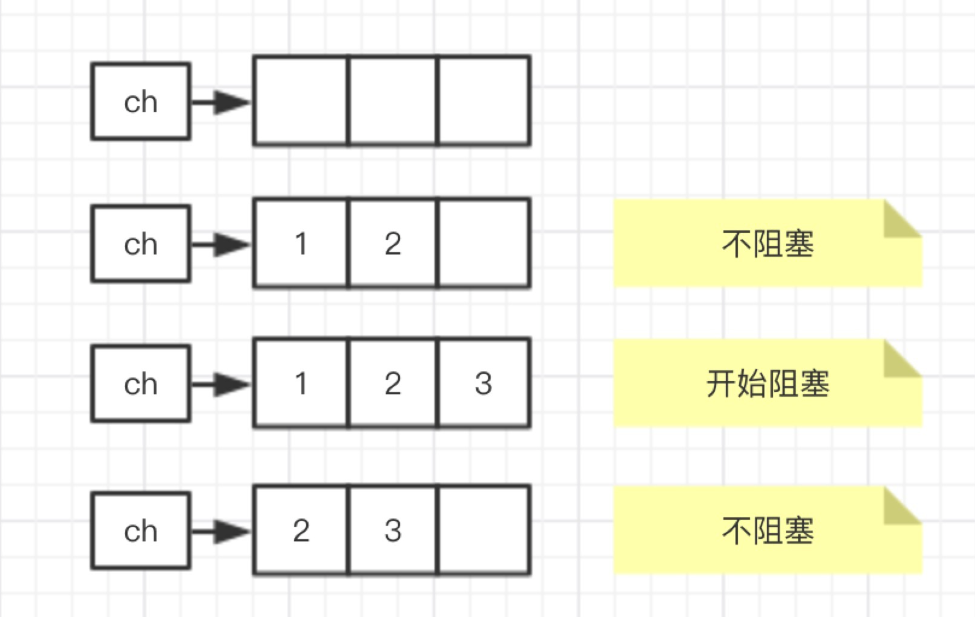
- 当他体内的容积被塞满后,就会阻塞 ,就会死锁
- 必须要让通道体内元素个数不大于其设定的容积大小,不然就会报错
通道有点类似于python的锁一样,谁拿到这个锁,谁就可以操作数据,通道就是谁进去了这个通道,谁就可以操作这个通道内的数据,当这个通道内塞满了的时候,就关门了,进不去了。
- 对通道循环取值:
1 | |
goroutine 阻塞死锁和友好退出
锁:
锁用来控制并发访问共享资源的一种同步机制避免多个goroutine同事访问和修改相同的数据,从而导致数据竞争或者不一致的状态,
1 | |
SELECT + CASE 多路复用
- select语句用于处理并发操作中的多个通道操作,它可以让你同事等待多个通道,并在其中任意一个通道就绪时执行对象的操作
- 与switch case语句类似,他有一系列的case分支和一个默认的分支,
- 每个分支case都会对应一个通道的通信(发送或者接收)过程,select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句,
- 如果多个case同时满足,select会随机选择一个去运行,
- 如果没有满足的case,则一直等待直到最后执行default分支,
- 如果没有任何通道就绪,且没有default子句,则sselect语句会阻塞,直到至少有一个通道就绪。
- select应用场景一:多路复用,通讯,同时监听多个通道,一旦某个通道可以进行读写操作,对应的case语句就会被执行。这种方式可以有效实现多个并发任务之间的协调和同步
1 | |
- select 应用的场景二:超时处理,结合selcet和time.After函数,事件对某个操作的超时控制,当某个操作超过一定时间没有完成时,可以执行响应的超时处理逻辑,一下两断代码一个基础版一个简单版的,:
1 | |
- 下面这个是常用的简化版的
1 | |
- select 场景三:非阻塞通信,通过定义default语句,实现非阻塞的通信操作,当没有任何通信操作可以立即进行时,default语句会被执行,可以写一下默认逻辑。(判断channel是否阻塞(或者说channel是否已经满了))
1 | |
- slelect场景四:.退出机制
1 | |
- 强调一下: 要跳出循环,一定要用break+ 具体标记,或者goto 标记也可以,否则其实不是真的退出,因为在goroutine里面,会不停地跑
1 | |
锁
锁是一种同步机制,用于控制对共享资源的访问,确保一次只有一个goroutine可以反问共享资源。
锁有两种状态:锁定和解锁,一旦有一个goroutine获得了锁,那其他goroutines将被阻塞。直到锁被释放
锁:互斥锁、读写锁
锁(互斥锁)简单解析
互斥锁:在并发执行时,多个goroutine同事读写一个数据,就会造成数据的读写混乱,
解决方式:加锁,加互斥锁,
方式:控制对共享资源的访问,让它可以却道在任何给定的时刻都只有一个线程或者说goroutine能够访问到被保护的临界区。
每一个
channel通道是解决协程同步,锁是解决协程(线程)访问资源优先性,
使用互斥锁时一定要注意,对资源(文件、数据等)操作完成
弊端:加了互斥锁之后,并发就变成了串行了,或者说,走到此处时,是串行,牺牲了效率,但是保证了数据安全性
互斥锁等待组
1 | |
读写锁
- 场景:读多写少,读是不需要加锁的,写需要加锁
- 解决:读写互斥锁
1 | |
sync.Map 并发安全映射(Map)
- Go内置的map 并不是并发安全的,所以高并发下使用sync.Map类型
- sync.Map不需要使用make()分配内存,使用另一种便捷方式:Store/Load等
1、并发安全性:sync.Map 在多个goroutines之间提供了并发安全的读取和写入操作,这意味着你可以同时在多个goroutines中访问和修改同一个映射,而不需要额外的锁或者同步机制去限制
2、自动扩容:sync.map在需要时会自动扩容以适应更多的键值对,无需手动管理容量问题
3、性能优化:sync.map在内部使用了一些性能优化策略,以提高并发访问的性能
1 | |